Wednesday, 22 July 2020
Anchored keys - scaling up a cluster without transferring values
Background
For background, the preferred way to scale up the storage capacity of a Infinispan cluster is to use distributed caches. A distributed cache stores each key/value pair on num-owners nodes, and each node can compute the location of a key (aka the key owners) directly.
Infinispan achieves this by statically mapping cache keys to num-segments consistent hash segments, and then dynamically mapping segments to nodes based on the cache’s topology (roughly the current plus the historical membership of the cache). Whenever a new node joins the cluster, the cache is rebalanced, and the new node replaces an existing node as the owner of some segments. The key/value pairs in those segments are copied to the new node and removed from the no-longer-owner node via state transfer.
| Because the allocation of segments to nodes is based on random UUIDs generated at start time, it is common (though less so after ISPN-11679 ), for segments to also move from one old node to another old node. |
Architecture
The basic idea is to skip the static mapping of keys to segments and to map keys directly to nodes.
When a key/value pair is inserted into the cache, the newest member becomes the anchor owner of that key, and the only node storing the actual value. In order to make the anchor location available without an extra remote lookup, all the other nodes store a reference to the anchor owner.
That way, when another node joins, it only needs to receive the location information from the existing nodes, and values can stay on the anchor owner, minimizing the amount of traffic.
Limitations
- Only one node can be added at a time
-
An external actor (e.g. a Kubernetes/OpenShift operator, or a human administrator) must monitor the load on the current nodes, and add a new node whenever the newest node is close to "full".
| Because the anchor owner information is replicated on all the nodes, and values are never moved off a node, the memory usage of each node will keep growing as new entries and nodes are added. |
- There is no redundancy
-
Every value is stored on a single node. When a node crashes or even stops gracefully, the values stored on that node are lost.
- Transactions are not supported
-
A later version may add transaction support, but the fact that any node stop or crash loses entries makes transactions a lot less valuable compared to a distributed cache.
- Hot Rod clients do not know the anchor owner
-
Hot Rod clients cannot use the topology information from the servers to locate the anchor owner. Instead, the server receiving a Hot Rod get request must make an additional request to the anchor owner in order to retrieve the value.
Configuration
The module is still very young and does not yet support many Infinispan features.
Eventually, if it proves useful, it may become another cache mode, just like scattered caches. For now, configuring a cache with anchored keys requires a replicated cache with a custom element anchored-keys:
<?xml version="1.0" encoding="UTF-8"?>
<infinispan
xmlns="urn:infinispan:config:11.0"
xmlns:anchored="urn:infinispan:config:anchored:11.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:infinispan:config:11.0
https://infinispan.org/schemas/infinispan-config-11.0.xsd
urn:infinispan:config:anchored:11.0
https://infinispan.org/schemas/infinispan-anchored-config-11.0.xsd">
<cache-container default-cache="default">
<transport/>
<replicated-cache name="default">
<anchored:anchored-keys/>
</replicated-cache>
</cache-container>
</infinispan>When the <anchored-keys/> element is present, the module automatically enables anchored keys and makes some required configuration changes:
-
Disables
await-initial-transfer -
Enables conflict resolution with the equivalent of
<partition-handling when-split="ALLOW_READ_WRITES" merge-policy="PREFER_NON_NULL"/>
The cache will fail to start if these attributes are explicitly set to other values, if state transfer is disabled, or if transactions are enabled.
Implementation status
Basic operations are implemented: put, putIfAbsent, get, replace, remove, putAll, getAll.
Functional commands
The FunctionalMap API is not implemented.
Other operations that rely on the functional API’s implementation do not work either: merge, compute, computeIfPresent, computeIfAbsent.
Performance considerations
Client/Server Latency
The client always contacts the primary owner, so any read has a (N-1)/N probability of requiring a unicast RPC from the primary to the anchor owner.
Writes require the primary to send the value to one node and the anchor address to all the other nodes, which is currently done with N-1 unicast RPCs.
In theory we could send in parallel one unicast RPC for the value and one multicast RPC for the address, but that would need additional logic to ignore the address on the anchor owner and with TCP multicast RPCs are implemented as parallel unicasts anyway.
Memory overhead
Compared to a distributed cache with one owner, an anchored-keys cache contains copies of all the keys and their locations, plus the overhead of the cache itself.
Therefore, a node with anchored-keys caches should stop accepting new entries when it has less than (<key size> + <per-key overhead>) * <number of entries not yet inserted> bytes available.
| The number of entries not yet inserted is obviously very hard to estimate. In the future we may provide a way to limit the overhead of key location information, e.g. by using a distributed cache. |
The per-key overhead is lowest for off-heap storage, around 63 bytes: 8 bytes for the entry reference in MemoryAddressHash.memory, 29 bytes for the off-heap entry header, and 26 bytes for the serialized RemoteMetadata with the owner’s address.
The per-key overhead of the ConcurrentHashMap-based on-heap cache, assuming a 64-bit JVM with compressed OOPS, would be around 92 bytes: 32 bytes for ConcurrentHashMap.Node, 32 bytes for MetadataImmortalCacheEntry, 24 bytes for RemoteMetadata, and 4 bytes in the ConcurrentHashMap.table array.
State transfer
State transfer does not transfer the actual values, but it still needs to transfer all the keys and the anchor owner information.
Assuming that the values are much bigger compared to the keys, the anchor cache’s state transfer should also be much faster compared to the state transfer of a distributed cache of a similar size. But for small values, there may not be a visible improvement.
The initial state transfer does not block a joiner from starting, because it will just ask another node for the anchor owner. However, the remote lookups can be expensive, especially in embedded mode, but also in server mode, if the client is not HASH_DISTRIBUTION_AWARE.
Tags: anchored keys state transfer
Wednesday, 01 March 2017
Checking Infinispan cluster health and Kubernetes/OpenShift
Modern applications and microservices often need to expose their health status. A common example is Spring Actuator but there are also many different ways of doing that.
Starting from Infinispan 9.0.0.Beta2 we introduced the HealthCheck API. It is accessible in both Embedded and Client/Server mode.
Cluster Health and Embedded Mode
The HealthCheck API might be obtained directly from EmbeddedCacheManager and it looks like this:
The nice thing about the API is that it is exposed in JMX by default:
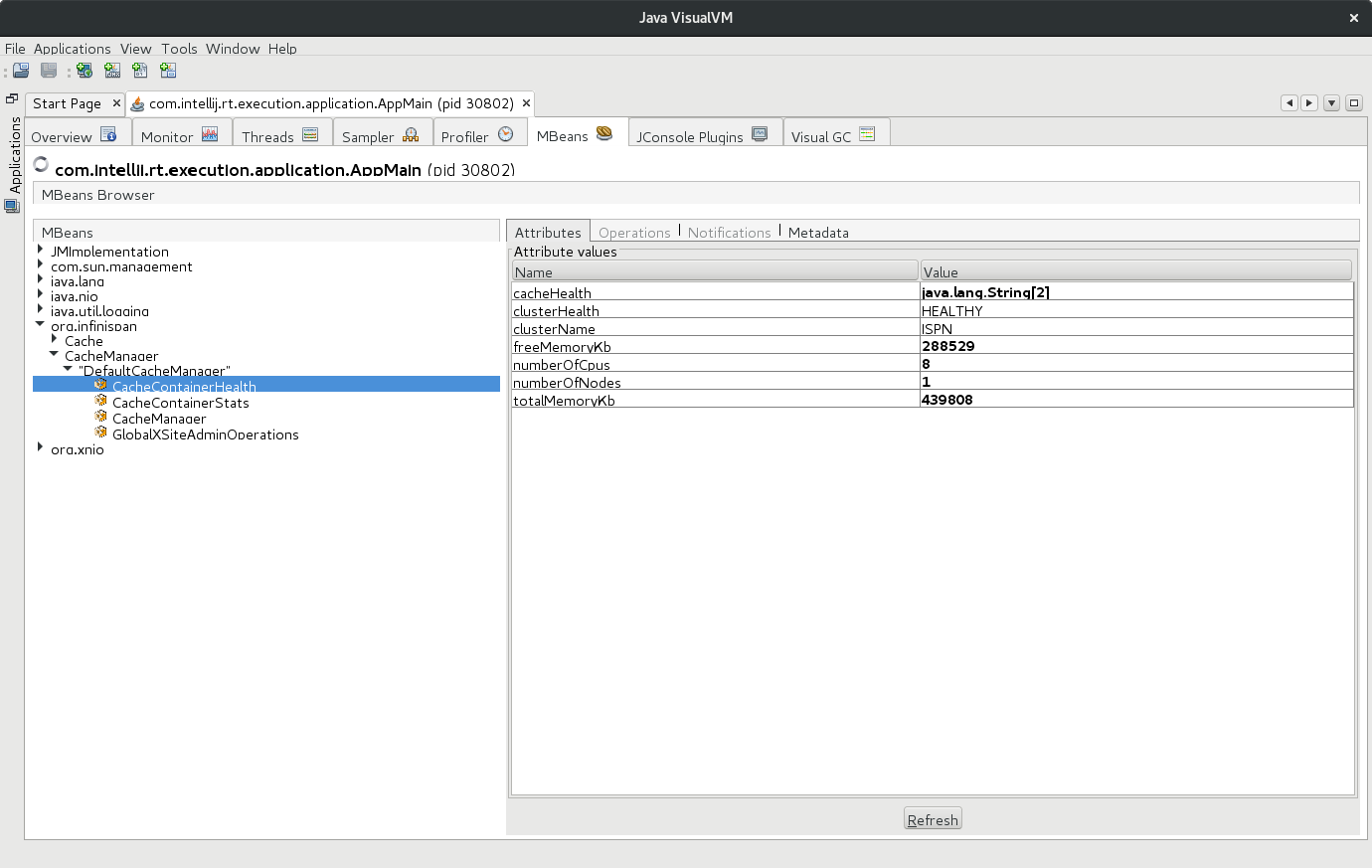
More information about using HealthCheck API in Embedded Mode might be found here:
Cluster Health and Server Mode
Since Infinispan is based on Wildfly, we decided to use CLI as well as built-in Management REST interface.
Here’s an example of checking the status of a running server:
Querying the HealthCheck API using the Management REST is also very simple:
Note that for the REST endpoint, you have to use proper credentials.
More information about the HealthCheckA API in Server Mode might be found here:
Cluster Health and Kubernetes/OpenShift
Monitoring cluster health is crucial for Clouds Platforms such as Kubernetes and OpenShift. Those Clouds use a concept of immutable Pods. This means that every time you need change anything in your application (changing configuration for the instance), you need to replace the old instances with new ones. There are several ways of doing that but we highly recommend using Rolling Updates. We also recommend to tune the configuration and instruct Kubernetes/OpenShift to replace Pods one by one (I will show you an example in a moment).
Our goal is to configure Kubernetes/OpenShift in such a way, that each time a new Pod is joining or leaving the cluster a State Transfer is triggered. When data is being transferred between the nodes, the Readiness Probe needs to report failures and prevent Kubernetes/OpenShift from doing progress in Rolling Update procedure. Once the cluster is back in stable state, Kubernetes/OpenShift can replace another node. This process loops until all nodes are replaced.
Luckily, we introduced two scripts in our Docker image, which can be used out of the box for Liveness and Readiness Probes:
At this point we are ready to put all the things together and assemble DeploymentConfig:
Interesting parts of the configuration:
-
lines 13 and 14: We allocate additional capacity for the Rolling Update and allow one Pod to be down. This ensures Kubernetes/OpenShift replaces nodes one by one.
-
line 44: Sometimes shutting a Pod down takes a little while. It is always better to wait until it terminates gracefully than taking the risk of losing data.
-
lines 45 - 53: The Liveness Probe definition. Note that when a node is transferring the data it might highly occupied. It is wise to set higher value of 'failureThreshold'.
-
lines 54 - 62: The same rule as the above. The bigger the cluster is, the higher the value of 'successThreshold' as well as 'failureThreshold'.
Feel free to checkout other articles about deploying Infinispan on Kubernetes/OpenShift:
-
http://blog.infinispan.org/2016/08/running-infinispan-cluster-on-openshift.html
-
http://blog.infinispan.org/2016/08/running-infinispan-cluster-on-kubernetes.html
-
http://blog.infinispan.org/2016/09/configuration-management-on-openshift.html
-
http://blog.infinispan.org/2016/10/openshift-and-node-affinity.html
-
http://blog.infinispan.org/2016/07/bleeding-edge-on-docker.html
Tags: openshift kubernetes state transfer health
Friday, 24 October 2014
Cross-Site Replication: state transfer is here!
Hello community.
Since the initial release of Cross-Site Replication, the state transfer between sites was really needed. When a new site is brought online, there was not way to synchronize the data between them. Finally, these days are over and it is possible synchronize geographically replicated sites. How to use is described in Infinispan’s Manual.
For the curious, the solution is described here.
Any question can be asked in the https://developer.jboss.org/en/infinispan/content?filterID=contentstatus%5Bpublished%5Dobjecttypeobjecttype%5Bthread%5D[forum], mailing list or directly with us in the IRC. If you found a bug please report it in here.
Happy coding, fellows.
Infinispan Team.
Tags: state transfer cross site replication
Monday, 17 December 2012
Infinispan 5.2.0.Beta6 is out!
5.2.0.Beta6 brings a new batch of fixes around Non-Blocking State Transfer, Map/Reduce and command line interface. But it’s not only that, it also brings a bran new pice of functionality: support of concurrent updates for non-transactional caches(ISPN-2552) . Prior Infinispan 5.2.0.Beta6, there was a high chance for a deadlock to occur when two threads concurrently update the same key. This caused significant performance costs and throughput degradation, linear to the amount of contention. This functionality is enabled by default even though a compatibility mode is still available. You can read more about it here.
For a detailed list of all the issues fixed please refer thehttps://issues.jboss.org/secure/ReleaseNote.jspa?projectId=12310799&version=12320690[ release notes].
You can download the distribution or the maven artifact. If you have any questions please check our forums, our mailing lists or ping us directly on IRC!
Cheers, Mircea
Tags: beta release state transfer
Sunday, 14 October 2012
Infinispan 5.2.0.Beta2 is out!
Infinispan 5.2.0.Beta2 contains a handful of bugfixes especially around the new Non-Blocking State Transfer functionality. For a detailed view of what has been fixed please refer to JIRA.
You can download the distribution or the maven artifact. If you have any questions please check our forums, our mailing lists or ping us directly on IRC!
Cheers, Mircea
Tags: beta release state transfer
Saturday, 01 September 2012
Infinispan 5.2.0.Alpha3 is out!
There are releases and releases. And this one is a big one, containing a bran new state transfer functionality. Designed and implemented by Dan Berindei and Adrian Nistor, the new Non Blocking State Transfer (NBST) has the following goals:
-
Minimize the interval(s) where the entire cluster can’t respond to requests because of a state transfer in progress.
-
Minimize the interval(s) where an existing member stops responding to requests because of a state transfer in progress.
-
Allow the performance of the cluster to drop during state transfer, but it should not throw any exception
Curious to see the magic behind it? This document is here to explain you NBST’s internal.
Besides NBST this release brings some other goodies:
-
A new IGNORE_RETURN_VALUES flag to help reduce the number of RPC calls and increasing performance (to be discussed at large by Galder Zamarreño in a following blog post)
-
A revamped and much nicer configuration for submodules such as cache loaders. More about it in Tristan Tarrant’s blog
-
for a complete list of the fixes/enhancements refer to JIRA
Another new thing this release brings is a change in versioning: we’ve aligned to JBoss' release versioning pattern. So the name is now Alpha3 vs ALPHA3(as per the old naming pattern). More about the reason for doing that in this blog post.
The complete list of issues/improvements addressed in this release is available in JIRA. As always, please give it a try and let us know what you think on the forums, irc or mailing lists!
Cheers,
Mircea
Tags: release alpha state transfer
Thursday, 21 June 2012
Fine-grained replication in Infinispan
[.underline]##
Sometimes we have a large object, possibly with lots of attributes or holding some binary data, and we would like to tell Infinispan to replicate only certain part of the object across the cluster. Typically, we wanna replicate only that part which we’ve just updated. This is where DeltaAware and Delta interfaces come to play. By providing implementations of these interfaces we can define fine-grained replication. When we put some effort into such such an enhancements, we would also like to speed up object marshalling and unmarshalling. Therefore, we’re going to define our own externalizers - to avoid slow default Java serialization.
The following code snippets are gathered in a complete example at https://github.com/mgencur/infinispan-examples/tree/master/partial-state-transfer This project contains a readme file with instructions on how to build and run the example. It is based on clustered-cache quickstart in Infinispan.
Implementing DeltaAware interface
So let’s look at our main object. For the purpose of this exercise, I defined a Bicycle class that consists of many components like frame, fork, rearShock, etc. This object is stored in a cache as a value under certain (not important) key. It might happen in our scenario that we update only certain components of the bike and in such case we want to replicate just those component changes.
Important methods here are (description taken from javadocs):
commit() - Indicates that all deltas collected to date has been extracted (via a call to delta()) and can be discarded. Often used as an optimization if the delta isn’t really needed, but the cleaning and resetting of internal state is desirable.
delta() - Extracts changes made to implementations, in an efficient format that can easily and cheaply be serialized and deserialized. This method will only be called once for each changeset as it is assumed that any implementation’s internal changelog is wiped and reset after generating and submitting the delta to the caller. We also need to define setters and getters for our members. Setter methods are, among other things, responsible for registering changes to the changelog that will be later used to reconstruct the object’s state. The externalizer for this class is only needed when cache stores are used. For the sake of simplicity, I don’t mention it here.
Implementing Delta interface
Actual object that will be replicated across the cluster is the implementation of Delta interface. Let’s look at the class. First, we need a field that will hold the changes - changeLog. Second, we need to define a merge() method. This method must be implemented so that Infinispan knows how to merge an existing object with incoming changes. The parameter of this method represents an object that is already stored in a cache, incoming changes will be applied to this object. We’re using a reflection here to apply the changes to the actual object but it is not necessary. We could easily call setter methods. The advantage of using reflection is that we can set those fields in a loop.
Another piece is a registerComponentChange() method. This is called by an object of the Bicycle class - to record changes to that object. The name of this method is not important.
Defining our own externalizer
Alright, so what remains is the externalizer definition for the Delta implementation. We implement AdvancedExternalizer interface and say that only changeLog object should be marshalled and unmarshalled when transfering data over the wire. A complete (almost) implementation of Delta interface is the following.
Tell Infinispan about the extra externalizer
We also need to configure Infinispan to use our special externalizer to marshall/unmarshall our objects. We can do it e.g. programatically by calling .addAdvancedExternalizer() on the serialization configuration builder.
You can see we’re also configuring transactions here. This is not necessary, though. We just aim to provide a richer example, removing transactional behavior is trully easy.
And here comes the "usage" part. Enclose cache calls by a transaction, retrieve a bicycle object from the cache, do some changes and commit them.
That’s it. What is eventually transferred over the wire is just the changeLog object. The actual bicycle object is reconstructed from incomming updates.
If all of this seem to be too complex to you, I have good news. Infinispan provides one implementation of DeltaAware interface whish is called AtomicHashMap (package org.infinispan.atomic). If this map is used as a value in key/value pairs stored in the cache, only puts/gets/removes performed to this map during a transaction are replicated to other nodes. Classes like Bicycle and BicycleDelta are not need then. Even registering the externalizer for AtomicHashMap is not needed, this is done automatically during registration of internal externalizers. However, one might want a class emulating a real-world object, not just a map. That’s the case when your own implementations of DeltaAware and Delta interfaces are the only way.
Tags: replication fine grained state transfer
Friday, 13 April 2012
Infinispan 5.1.4.CR1 is here!
Infinispan 5.1.4.CR1 is out now with minor improvements focusing on third party library upgrades such as JBoss Transactions and JGroups, and state transfer related issues, and reducing the resource consumption of testsuite.
Full details of what has been fixed can be found here, and if you have feedback, please visit our forums. Finally, as always, you can download the release from here.
Cheers, Galder
Tags: state transfer release candidate release
Wednesday, 21 September 2011
Next Infinispan 5.1.0 alpha hits the streets!
Infinispan 5.1.0.ALPHA2 "Brahma" is out now containing a consolidated push-based approach for both state transfer in replicated caches and rehashing in distributed ones. The new changes don’t have great impact on the distributed cache users, but for those that relied on state transfer, it’s definitely good news :). State transfer now works in such way that when a node joins, all nodes in the cluster push state to it, rather than the new node getting it from the cluster coordinator. As a result of this, the task of providing the state is paralellized, reducing the load on state providers.
On top of that, this Infinispan release is the first one to integrate JGroups 3.0 which brings plenty of API changes that simplifies a lot of the Infinispan/JGroups interaction. If you want to find out more about the new JGroups version, make sure you check Bela’s blog and the brand new JGroups manual.
Please keep the feedback coming, and as always, you can download the release from here and you get further details on the issues addressed in the changelog.
Cheers, Galder
Tags: rehashing state transfer